In this Java article I walk you through designing a micro benchmark to assess the performance between String + (plus operator), String.concat method, StringBuilder.append method and StringBuffer.method. These are all different ways using which we can append two string values. This is a well grinded topic over the period and everybody knows the result of who will win and who will have the least performance. Though the fact is established, I couldn’t find any detailed micro benchmark stats and graph on this topic in Internet while doing a casual search.
I also wanted to put JMH to use for a proper scenario. JMH is a Java Microbenchmark Harness (JMH), a open source software by OpenJDK to create benchmarks for Java programs. So I wrote a small Java program and annotated with JMH annotations to record performance and drew a graph out of it. Before going into the micro benchmark let us understand the difference between using StringBuilder, String Buffer, String.concat and + operator to append strings.
//DIFFERENCE 1 String a = null; String b = "foo"; String c = a + b; // c = nullfoo String d = b.concat(a); // NPE String e = a.concat(b); // NPE //DIFFERENCE 2 String x = "1" + 2; // x = 12 String y = "1".concat(2); // compilation error
String c = a + b; statement is converted as below by Java compiler.
c = new StringBuilder() .append(a) .append(b) .toString();
So which should we use? It is always better to use StringBuilder.append to concatenate two string values. Let us cement this statement using the below micro benchmark.
Following micro benchmark is designed to measure the performance of calling StringBuilder.append, StringBuffer.append, String.concat and String + within a for-loop for n number of times. JMH benchmark is designed as follows,
package com.javapapers.java.benchmark;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Warmup;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
@State(Scope.Thread)
public class StringConcatenationBenchmark {
StringBuilder stringBuilder1;
StringBuilder stringBuilder2;
StringBuffer stringBuffer1;
StringBuffer stringBuffer2;
String string1;
String string2;
/*
* re-initializing the value after every iteration
*/
@Setup(Level.Iteration)
public void init() {
stringBuilder1 = new StringBuilder("foo");
stringBuilder2 = new StringBuilder("bar");
stringBuffer1 = new StringBuffer("foo");
stringBuffer2 = new StringBuffer("bar");
string1 = new String("foo");
string2 = new String("bar");
}
@State(Scope.Benchmark)
public static class BenchmarkState {
volatile long builderConcatCount = 1;
volatile long bufferConcatCount = 1;
volatile long stringPlusCount = 1;
volatile long stringConcatCount = 1;
}
/*
* want to measure the progress from call to call so using the
* SingleShotTime mode
*/
@Benchmark
@Warmup(iterations = 5, batchSize = 1)
@Measurement(iterations = 100, batchSize = 1000)
@BenchmarkMode(Mode.SingleShotTime)
public StringBuilder stringBuilder(BenchmarkState state) {
StringBuilder stringBuilder = null;
for (long j = 0; j < state.builderConcatCount; j++) {
stringBuilder = stringBuilder1.append(stringBuilder2);
}
state.builderConcatCount++;
// to avoid dead code optimization returning the value
return stringBuilder;
}
@Benchmark
@Warmup(iterations = 5, batchSize = 1)
@Measurement(iterations = 100, batchSize = 1000)
@BenchmarkMode(Mode.SingleShotTime)
public StringBuffer stringBuffer(BenchmarkState state) {
StringBuffer stringBuffer = null;
for (long j = 0; j < state.bufferConcatCount; j++) {
stringBuffer = stringBuffer1.append(stringBuffer2);
}
state.bufferConcatCount++;
// to avoid dead code optimization returning the value
return stringBuffer;
}
/*
* want to measure the progress from call to call so using the
* SingleShotTime mode
*/
@Benchmark
@Warmup(iterations = 5, batchSize = 1)
@Measurement(iterations = 100, batchSize = 1000)
@BenchmarkMode(Mode.SingleShotTime)
public String stringPlus(BenchmarkState state) {
String string = null;
for (long j = 0; j < state.stringPlusCount; j++) {
string = string1 + string2;
}
state.stringPlusCount++;
return string;
}
@Benchmark
@Warmup(iterations = 5, batchSize = 1)
@Measurement(iterations = 100, batchSize = 1000)
@BenchmarkMode(Mode.SingleShotTime)
public String stringConcat(BenchmarkState state) {
String string = null;
for (long j = 0; j < state.stringConcatCount; j++) {
string = string1.concat(string2);
}
state.stringConcatCount++;
// to avoid dead code optimization returning the value
return string;
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StringConcatenationBenchmark.class.getSimpleName())
.threads(1).forks(1).shouldFailOnError(true).shouldDoGC(true)
.jvmArgs("-server").build();
new Runner(options).run();
}
}
pom.xml used to build the JMH project. Once the project is built, execute it from command prompt using the following command.
mvn clean install exec:exec
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.javapapers.java.benchmark</groupId>
<artifactId>java-benchmark-string</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>Java Benchmark String Concatenation</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<jmh.version>1.10.3</jmh.version>
<javac.target>1.7</javac.target>
</properties>
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<compilerVersion>${javac.target}</compilerVersion>
<source>${javac.target}</source>
<target>${javac.target}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.4.0</version>
<configuration>
<executable>java</executable>
<arguments>
<argument>-classpath</argument>
<classpath />
<argument>com.javapapers.java.benchmark.StringConcatenationBenchmark</argument>
</arguments>
</configuration>
</plugin>
</plugins>
</build>
</project>
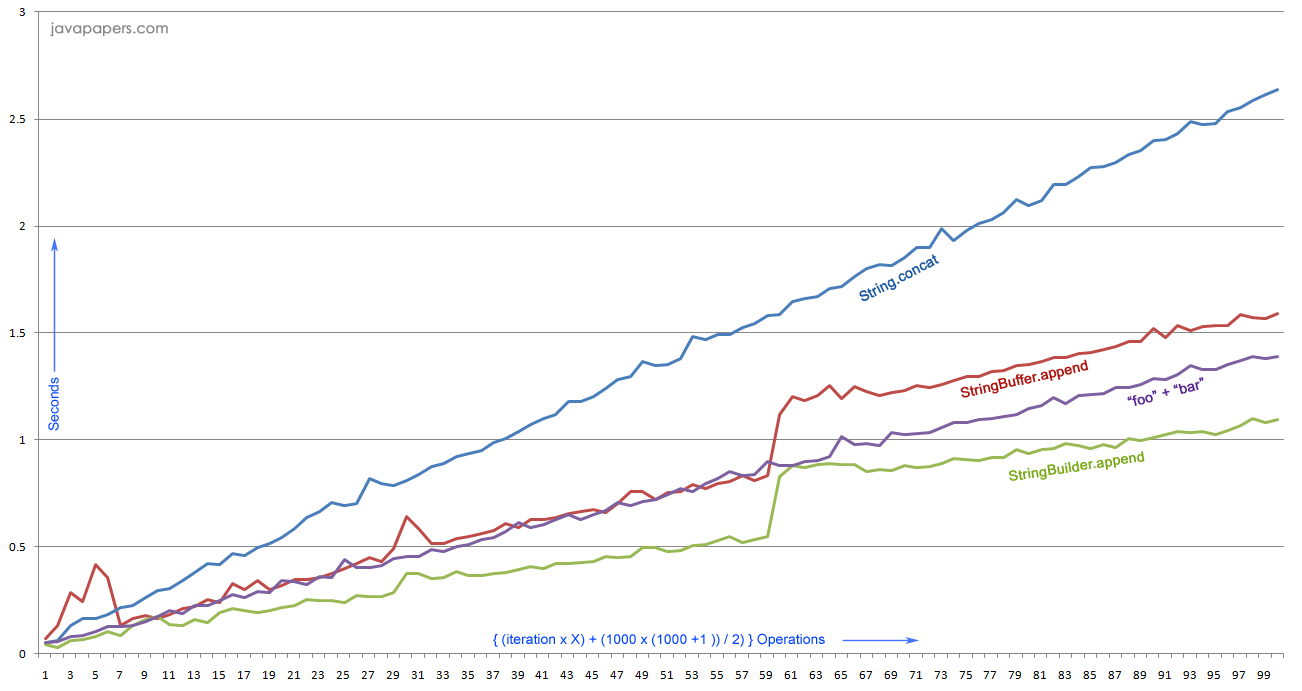
I have run the benchmark for insane number of times to get the detail stats. I am not sure where in the world this kind of scenario will be required. For experimentation, you can reduce the iteration and batchSize and see the results. I have recorded the number for different combinations and the logical results are the same. If you are interested in the detailed numbers, the raw JMH output file is attached at the end of this article. For the iterations (100) and batchSize (1000) defined in the program the following is the execution count.
Iteration 1: 501500 Appends! batch call 1 - loop (append) 1 time batch call 2 - loop (append) 2 time ... batch call 1000 - loop (append) 1000 time Iteration 2: 1500500 Appends! batch call 1 - loop (append) 1001 time batch call 2 - loop (append) 1002 time ... batch call 1000 - loop (append) 2000 time ... Iteration 100: 99500500 Appends! batch call 1 - loop (append) 99001 time batch call 2 - loop (append) 99002 time ... batch call 1000 - loop (append) 100000 time
How the total number of appends per iteration is calculated:
(x+1) + (x+2) + (x+3) + ... + (x+n) = nx + ( n(n+1)/2 ) 99001 + 99002 + ... + 100000 = (99000x1000) + ( 1000(1000+1)/2 ) = 99500500
Do not worry about the about numbers and all these calculations. I am just trying to show off my Math skills. We are interested in the outcome, scroll above and go to the graph and click to see the larger version.
| StringBuilder.append | String + | StringBuffer.append | String.concat |
|---|---|---|---|
| Best performance for any number of iterations. | Less than 1000 iterations almost similar to StringBuilder.append. | Third in performance for huge numbers. | The worst is performance for huge numbers. |
| Use this always for string concatenation. | As the iteration count increases, gap in performance widens marginally with StringBuilder. | Till approximately 5 million iterations, this gives the worst performance among all. | Comes third for iterations less than approximately 5 million. |
StringBuffer.append is really worse for small numbers. The culprit is the synchronization of append method for thread safety. So stay away from it, if your program does not require synchronization. Unless if you need synchronization, StringBuilder.append always gives the best performance and it is the way to go.
If you feel ‘+’ is convenient and improves readability, it can be used if you are doing small number of appends (where there won’t be loops of large count). ‘+’ operator has no significant difference in performance with StringBuilder for small number of appends. As explained earlier, + internall uses StringBuilder only.
JMH raw performance reports
The micro benchmark tests were run on a silent machine with following,
If you want to measure the performance micro benchmark without loops, following code will help. This code will execute each benchmark method the fixed number of iterations and present the results with min, avg, max and standard deviation. I have given you the code and running it to see the output result is an exercise for you!
package com.javapapers.java.benchmark;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Warmup;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
@State(Scope.Thread)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class StringConcatAvgBenchmark {
StringBuilder stringBuilder1;
StringBuilder stringBuilder2;
StringBuffer stringBuffer1;
StringBuffer stringBuffer2;
String string1;
String string2;
/*
* re-initializing the value after every iteration
*/
@Setup(Level.Iteration)
public void init() {
stringBuilder1 = new StringBuilder("foo");
stringBuilder2 = new StringBuilder("bar");
stringBuffer1 = new StringBuffer("foo");
stringBuffer2 = new StringBuffer("bar");
string1 = new String("foo");
string2 = new String("bar");
}
@Benchmark
@Warmup(iterations = 10)
@Measurement(iterations = 100)
@BenchmarkMode(Mode.AverageTime)
public StringBuilder stringBuilder() {
// operation is very thin and so consuming some CPU
Blackhole.consumeCPU(100);
return stringBuilder1.append(stringBuilder2);
// to avoid dead code optimization returning the value
}
@Benchmark
@Warmup(iterations = 10)
@Measurement(iterations = 100)
@BenchmarkMode(Mode.AverageTime)
public StringBuffer stringBuffer() {
Blackhole.consumeCPU(100);
// to avoid dead code optimization returning the value
return stringBuffer1.append(stringBuffer2);
}
@Benchmark
@Warmup(iterations = 10)
@Measurement(iterations = 100)
@BenchmarkMode(Mode.AverageTime)
public String stringPlus() {
Blackhole.consumeCPU(100);
return string1 + string2;
}
@Benchmark
@Warmup(iterations = 10)
@Measurement(iterations = 100)
@BenchmarkMode(Mode.AverageTime)
public String stringConcat() {
Blackhole.consumeCPU(100);
// to avoid dead code optimization returning the value
return string1.concat(string2);
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StringConcatAvgBenchmark.class.getSimpleName())
.threads(1).forks(1).shouldFailOnError(true).shouldDoGC(true)
.jvmArgs("-server").build();
new Runner(options).run();
}
}



Comments are closed for "Java String vs StringBuilder vs StringBuffer Concatenation Performance Micro Benchmark".
Is that first column in the 4-column table supposed to be “StringBuilder.append” rather than “StringBuffer.append”?
Hi Joe,
Thanks for this artical. So many times my colleagues and me have a discussion about the differnces between String, StringBuilder and StringBuffer. Now we have clear idea and we have got new points with these artical. Thanks once again Joe.
Great discussion Joe. Yes it has an issue in the table. Best performance from StringBuilder.append(). Is it ?
@Basil Bourque, yes it is StringBuilder.append
Thanks a lot, I have fixed it.
Good Stuff!! Joe.